INTRODUCTION
In this post, we’ll learn a powerful technique for scanning arrays in Excel.
The SCAN and REDUCE functions in Excel allow us to apply a function to each element of an array and, as each function call returns, save the result in an accumulator which is passed as an argument to the function call on the next array element.
As a simple example, the following function starts by assigning 0 as the initial value of the accumulator. It then scans over the sequence of integers {1..10} and, for each integer, it adds the current array element to the value of the accumulator after the previous iteration. As each addition is completed, the accumulator is updated.
=SCAN(0,SEQUENCE(10),LAMBDA(acc, curr, acc + curr))
So, the scan proceeds like this:
0, 0+1(=1), 1+2(=3), 3+3(=6), 6+4(=10), 10+5(=15), ..., 45+10(=55)
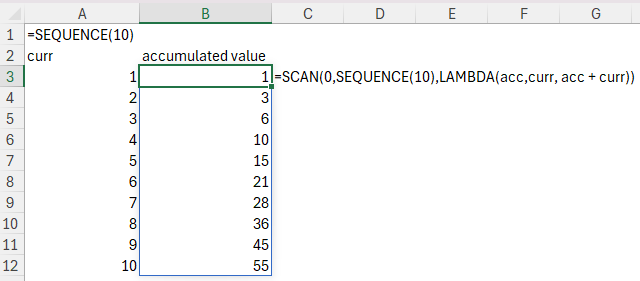
The REDUCE function works similarly, only it doesn’t return the intermediate values. It only returns the final accumulated value. In the example above, the final accumulated value is 55. Both of these functions are incredibly important to modern formula development and modeling in Excel.
Sometimes, we may have a need to iterate over 2 arrays with SCAN or REDUCE. A classic example of needing to do this is with a so-called “gaps and islands” problem, where we need to scan over an array and a drop-shifted copy of that array to determine the boundaries of sequences of consecutive integers.
It’s somewhat easy to do this using what I’ll refer to as an “index scan”. Instead of iterating over the arrays separately, we iterate over an index of row numbers, then use the INDEX function to pull values out of correlated positions in one or more arrays.
=LET(
d, SORT(Sheet3!$B$3:$B$16),
SCAN(
0,
SEQUENCE(ROWS(d)),
LAMBDA(a, b, IF(b = 1, a, IF(INDEX(d, b, 1) - INDEX(d, b - 1, 1) > 1, a + 1, a)))
)
)
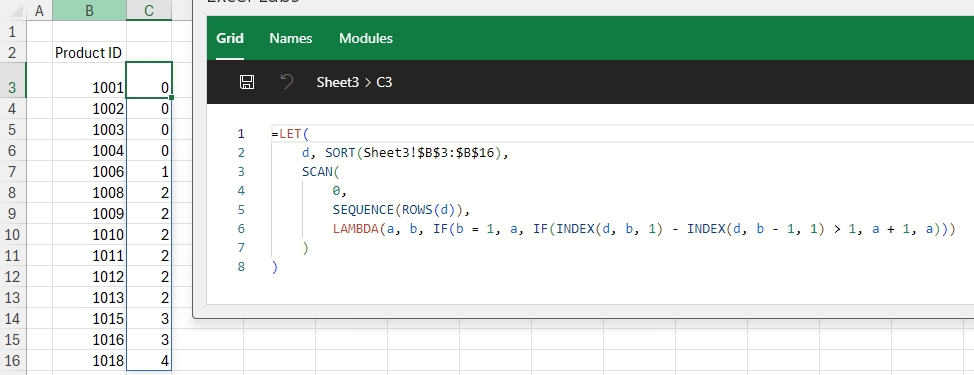
Here, the SCAN is iterating over a sequence of integers from 1 through the number of rows in the array d (the data in column B). The logic inside the LAMBDA function within SCAN is:
If b is 1, then it’s the first row, just set the accumulated value for this iteration to the initial value (0). Otherwise, b is not 1. Now, if the value on row b of d minus the value of row b-1 of d is greater than 1, then the current row and the previous row are not sequential integers. Since that’s the case, increase the accumulated value by 1. If the difference is not greater than 1, then it’s 1, so the accumulator is not changed.
The result is we get a unique integer ID for each sequence of consecutive integers.
So, this is just one example of when this kind of “index scan” is needed. In my opinion, remembering the syntax of that function is somewhat awkward, so it would be helpful if we had a version of SCAN into which we could pass not one, but two arrays.
F#’s List.fold2
The F# language has a collection of functions for working with lists. One such function is called List.fold2. This function behaves similarly to REDUCE except it allows us to pass 2 arrays instead of just one. From the documentation:
Count the number of times the coins match:
type CoinToss = Head | Tails
let inputs1 = [Tails; Head; Tails]
let inputs2 = [Tails; Head; Head]
(0, inputs1, inputs2) |||> List.fold2 (fun acc input1 input2 ->
match (input1, input2) with
| Head, Head -> acc + 1
| Tails, Tails -> acc + 1
| _ -> acc)
This deliberately trivial example returns 2, because in two cases, the correlated elements of the two arrays are equal, and the function increments the accumulator after each such case.
In this post, I’ll show you a LIST.FOLD2 LAMBDA function that mimics this behavior. As we’ll see, the internals of the function are similar to the “index scan” discussed above.
LIST.FOLD2
Here’s one way that we can wrap this functionality as an Excel LAMBDA function.
/*
LAMBDA implementation of F#'s List.fold2, which provides something similar to REDUCE, but
allows iteration over 2 lists instead of a single array.
This version allows us to use either REDUCE or SCAN, depending on whether we want the intermediate
results.
function is a function of three arguments:
accumulator
valueFromList1
valueFromList2
Trivial Example, count the number of matching items:
=LIST.FOLD2(REDUCE)(0,{"Tails";"Heads";"Tails"},{"Tails";"Heads";"Heads"},LAMBDA(a,b,c,IF(b=c,a+1,a)))
*/
LIST.FOLD2 = LAMBDA(scan_or_reduce,
LAMBDA(initial_value, list1, list2, function,
LET(
// ensure they're both lists and not 2d arrays or rows
list1Col, TOCOL(list1),
list2Col, TOCOL(list2),
// If they're different lengths, only iterate over rows available in both
array_index, SEQUENCE(MIN(ROWS(list1Col), ROWS(list2Col))),
scan_or_reduce(
initial_value,
array_index,
LAMBDA(a, b, function(a, INDEX(list1Col,b,1), INDEX(list2Col,b,1)))
)
)
)
);
LIST.FOLD2 is a curried function that takes five arguments:
- scan_or_reduce – one of either the SCAN or REDUCE functions, depending on how we want the function to behave
- initial_value – the initial value for the accumulator
- list1 – the first list to iterate over
- list2 – the second list to iterate over
- function – a function of three arguments – accumulator, valueFromList1, valueFromList2. This function uses one or more of its arguments to set the value of the accumulator for an iteration.
Because the function is curried, we can easily derive two functions from the code above:
REDUCE2 = LIST.FOLD2(REDUCE);
SCAN2 = LIST.FOLD2(SCAN);
Each of these functions now returns the inner function of LIST.FOLD2 (the part beginning LAMBDA(initial_value, … )
This image shows the use of SCAN2 to build the same island IDs as the example discussed previously.
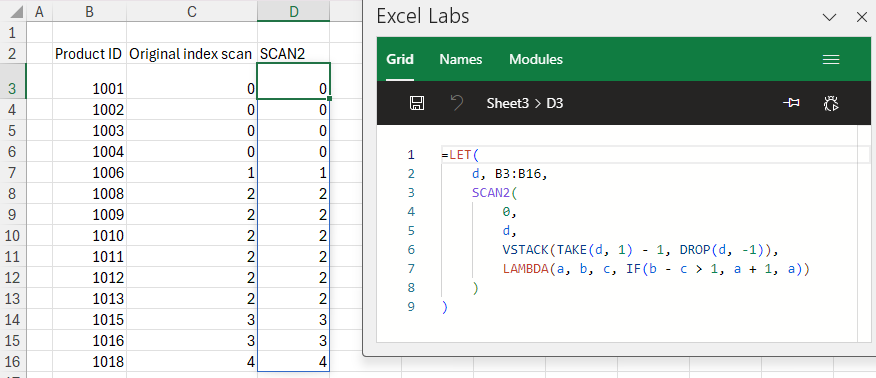
As you can see, because the tricky INDEX logic is hidden in the function, the formula is simplified somewhat (although admittedly the process of building list2 is somewhat tedious).
While we’re at it, let’s just fix that:
DROPSHIFT = LAMBDA(array, VSTACK(TAKE(array,1)-1,DROP(array,-1)));
=LET(d,B3:B16,SCAN2(0,d,DROPSHIFT(d),LAMBDA(a,b,c,IF(b-c>1,a+1,a))))
This kind of index scan of a drop-shifted array or two separate arrays comes up surprisingly frequently. In this particular case, we’re scanning over the array of data and the array of data with the last item removed and an artificial item placed at the top of the array.
Let’s look at the function within SCAN2:
LAMBDA(a,b,c,IF(b-c>1,a+1,a))
This is the function that accepts as arguments the accumulator, the value from list1 and the value from list2. The logic within is drastically simplified because these arguments are already values from the lists – we don’t need to look them up with INDEX. So the logic is simply: “if the difference between the two values is greater than 1, then increment the accumulator, otherwise don’t”.
Let’s take a look at how LIST.FOLD2 works.
BREAKDOWN
As a reminder:
LIST.FOLD2 = LAMBDA(scan_or_reduce,
LAMBDA(initial_value, list1, list2, function,
LET(
// ensure they're both lists and not 2d arrays or rows
list1Col, TOCOL(list1),
list2Col, TOCOL(list2),
// If they're different lengths, only iterate over rows available in both
array_index, SEQUENCE(MIN(ROWS(list1Col), ROWS(list2Col))),
scan_or_reduce(
initial_value,
array_index,
LAMBDA(a, b, function(a, INDEX(list1Col,b,1), INDEX(list2Col,b,1)))
)
)
)
);
First, we convert both list1 and list2 to column vectors using the TOCOL function.
LET(
// ensure they're both lists and not 2d arrays or rows
list1Col, TOCOL(list1),
list2Col, TOCOL(list2),
Doing this simplifies the code that follows. Next, we create the index over which we’ll scan to retrieve values from list1Col and list2Col:
// If they're different lengths, only iterate over rows available in both
array_index, SEQUENCE(MIN(ROWS(list1Col), ROWS(list2Col))),
Here, we are accounting for the possibility of list1Col and list2Col being of different length (which would be a problem) and specifying that the index should be only those integers between 1 and the minimum of the number of rows in each of the column vectors. If one happens to be longer than the other, those additional rows will not be processed.
Next, recall that the first parameter is scan_or_reduce. When we use LIST.FOLD2, we will pass either SCAN or REDUCE as an argument, and the scan_or_reduce parameter will behave accordingly.
scan_or_reduce(
initial_value,
array_index,
LAMBDA(a, b, function(a, INDEX(list1Col,b,1), INDEX(list2Col,b,1)))
)
So, scan_or_reduce is either SCAN or REDUCE. The arguments we pass to it then must match those expected by each of those Excel functions.
- initial_value
- array – which here is referred to as “array_index”
- lambda
We pass the initial_value supplied by the call from the spreadsheet into either SCAN or REDUCE. Similarly, the array_index defined by the minimum number of rows in either list1Col or list2Col is the array that will be iterated over. The LAMBDA function is a function of two parameters – the accumulator a and the value of the array index b. The logic within the LAMBDA is then a call to the function that was supplied to LIST.FOLD2’s function argument. As mentioned before, that function is a three-parameter function:
- Accumulator
- valueFromList1
- valueFromList2
Here we are passing the accumulator a directly into the function along with the index calls to row b of list1Col and list2Col. Whatever logic is present in that function of three arguments then processes each iteration accordingly.
And that really is it. By parameterizing both whether we’re using SCAN or REDUCE and by parameterizing the logic applied within the scan, LIST.FOLD2 is a very flexible function.
SUMMARY
In this post I showed you a way to implement versions of SCAN and REDUCE that can iterate over two correlated arrays using a function called LIST.FOLD2.
By using Excel’s ability to pass functions as arguments, we can reduce code duplication and quickly create the SCAN2 and REDUCE2 functions as derivatives of LIST.FOLD2.
I hope you’ve found the post interesting and that it will inspire you to solve problems you encounter frequently with reusable and flexible LAMBDA functions!
Leave a Reply