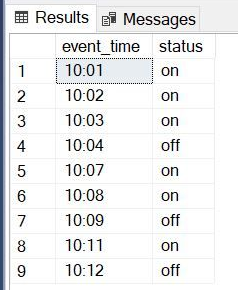
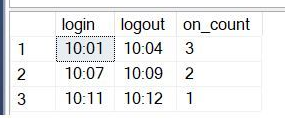
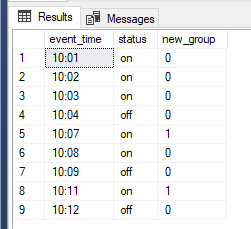
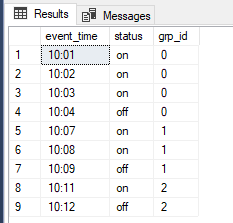
The full script for this post can be downloaded here.
The following post was written primarily in Postgres 14 and tested in both Postgres and MySQL.
While the data generation and use of EXCEPT are not supported natively in MySQL, the principles of row comparisons are equivalent.
Setup
To demonstrate how a row constructor comparison can be confusing, let’s create some dummy data with two columns of integers:
--create a table to hold some random integers
drop table if exists random_numbers;
create temp table random_numbers (a int, b int);
--create 100 rows of random integers
--between 0 and 50
insert into random_numbers (a, b)
select floor(random()*50), ceiling(random()*50)
from generate_series(1,10000);
Comparisons
PostgreSQL allows us to compare two sets of values using what is known as a row constructor comparison.
A row can be constructed with parentheses, like this:
--with columns in a query
(a_column, b_column)
--or with literals
(10, 40)
We can create complex rows in this way and then compare them with each other.
For example:
(a_column, b_column) = (10, 40)
This can be incredibly powerful and is a useful shortcut for complex logic.
However, the usual Spiderman caveat applies.
Comparing two row constructors is not always intuitive.
= operator
Consider this:
select 'This: "where (a,b) = (10,40)"' as message, count(*)
from (
select a, b
from random_numbers
where (a,b) = (10,40)
) x
union all
select 'Is the same as: "where a = 10 and b = 40"' as message, count(*)
from (
select a, b
from random_numbers
where a = 10 and b = 40
) x
union all
select 'Subtracting one from the other using "except" gives us' as message, count(*)
from (
select a, b
from random_numbers
where a = 10 and b = 40
except
select a, b
from random_numbers
where (a,b) = (10,40)
) x;
Which for the random data created when I wrote this post, returns this:
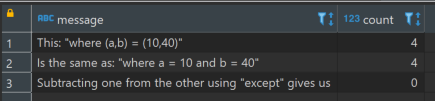
This is straightforward enough. Put simply: is the left side equal to the right side?
Intuitively, we expect a comparison between each “column” from the left side with the corresponding “column” of the right side. For the equals operator, it works how we expect.
<> operator
Consider this:
select 'This: "where (a,b) <> (10,40)"' as message, count(*)
from (
select a, b
from random_numbers
where (a,b) <> (10,40)
) x
union all
select 'Is not the same as: "where a <> 10 and b <> 40"' as message, count(*)
from (
select a, b
from random_numbers
where a <> 10 and b <> 40
) x
union all
select 'It''s the same as: "where a <> 10 or (a = 10 and b <> 40)"' as message, count(*)
from (
select a, b
from random_numbers
where a <> 10 or (a = 10 and b <> 40)
) x
union all
select 'Subtracting row 1 from row 3 using "except" gives us' as message, count(*)
from (
select a, b
from random_numbers
where a <> 10 or (a = 10 and b <> 40)
except
select a, b
from random_numbers
where (a,b) <> (10,40)
) x;
Which gives us:
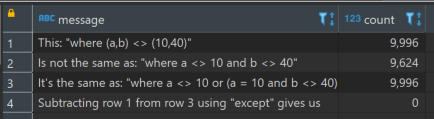
This may not appear as intuitive. But think about it this way: as long as one of the two conditions is met, then we consider the entire condition met.
When comparing two rows with the <> operator, if even one column is different, then the rows are different
We can either have a <> 10 and b = anything, or we can have a = 10 and b <> 40. Since both of those conditions together are equivalent to b <> 40 and a = anything, it doesn’t need to be specified.
Pretty straightforward when you think about if for a second.
Things are less intuitive when we move to other operators.
< operator
Consider:
select 'This: "where (a,b) < (10,40)"' as where_clause, count(*)
from (
select a, b
from random_numbers
where (a,b) < (10,40)
) x
union all
select 'Is not the same as: "where a < 10 and b < 40"' as where_clause, count(*)
from (
select a, b
from random_numbers
where a < 10 and b < 40
) x
union all
select 'It''s the same as: "where a < 10 or (a = 10 and b < 40)"' as where_clause, count(*)
from (
select a, b
from random_numbers
where a < 10 or (a = 10 and b < 40)
) x
union all
select 'Subtracting row 1 from row 3 using "except" gives us' as message, count(*)
from (
select a, b
from random_numbers
where a < 10 or (a = 10 and b < 40)
except
select a, b
from random_numbers
where (a,b) < (10,40)
) x;
We get this:
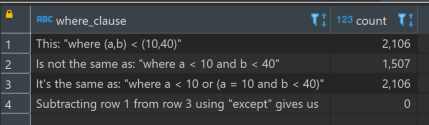
According to the documentation:
For the <, <=, > and >= cases, the row elements are compared left-to-right, stopping as soon as an unequal or null pair of elements is found. If either of this pair of elements is null, the result of the row comparison is unknown (null); otherwise comparison of this pair of elements determines the result
So, we are comparing one row with another, column-wise from left to right.
- Is a less than 10? If yes, include the row in the output. If not:
- Is a equal to 10 and b less than 40? If yes, include the row in the output.
The notable omission here is where b is less than 40 but a is greater than 10. Why?
Well, read the quote above again.
Specifically:
stopping as soon as an unequal or null pair of elements is found
The implication here is that each subsequent comparison assumes equality in the prior comparison(s). So, the “2nd” comparison of b with 40 assumes equality between a and 10.
And if that wasn’t confusing enough.
<= operator
Consider:
select 'This: "where (a,b) <= (10,40)"' as where_clause, count(*)
from (
select a, b
from random_numbers
where (a,b) <= (10,40)
) x
union all
select 'Is not the same as: "where a <= 10 and b <= 40"' as where_clause, count(*)
from (
select a, b
from random_numbers
where a <= 10 and b <= 40
) x
union all
select 'It''s the same as: "where a < 10 or (a = 10 and b <= 40)"' as where_clause, count(*)
from (
select a, b
from random_numbers
where a < 10 or (a = 10 and b <= 40)
) x
union all
select 'Subtracting row 1 from row 3 using "except" gives us' as message, count(*)
from (
select a, b
from random_numbers
where a < 10 or (a = 10 and b <= 40)
except
select a, b
from random_numbers
where (a,b) <= (10,40)
) x;
That code gives us:
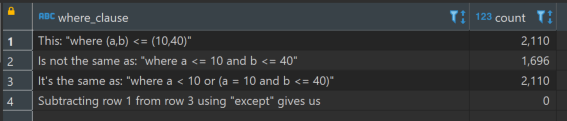
- If a is less than 10, then include the row in the output, otherwise:
- If a is equal to 10 and b is less than or equal to 40, then include the row in the output
We might have expected the first condition to be:
- If a is less than or equal to 10
But again:
stopping as soon as an unequal or null pair of elements is found
So, if the first comparison was actually a<=10, those rows where a=10 would not cause the evaluation to stop, the implication being that it would be including rows where a < 10 and b = anything as well as a = 10 and b = anything, after which rows where a = 10 and b <= 40 would be evaluated. This latter evaluation is a subset of (a = 10 and b = anything), and so becomes entirely redundant.
This behavior is similarly expressed with >= and >, but I won’t elaborate here, though they are included in the example script.
In summary
PostgreSQL allows us to use row constructors to compare sets of values.
The operators supported for such comparisons are =, <>, <, <=, > or >=
= and <> work as we might expect.
The other operators are evaluated from left-to-right and stop evaluating when the first unequal non-null comparison is encountered. Subsequent comparisons assume equality of the prior comparisons.